The world's best development agencies in one place
Vetted agencies, software development teams, and team augmentation services at your fingertips.
or
A TALENT COMMUNITY TRUSTED BY

WHY PANGEA.AI
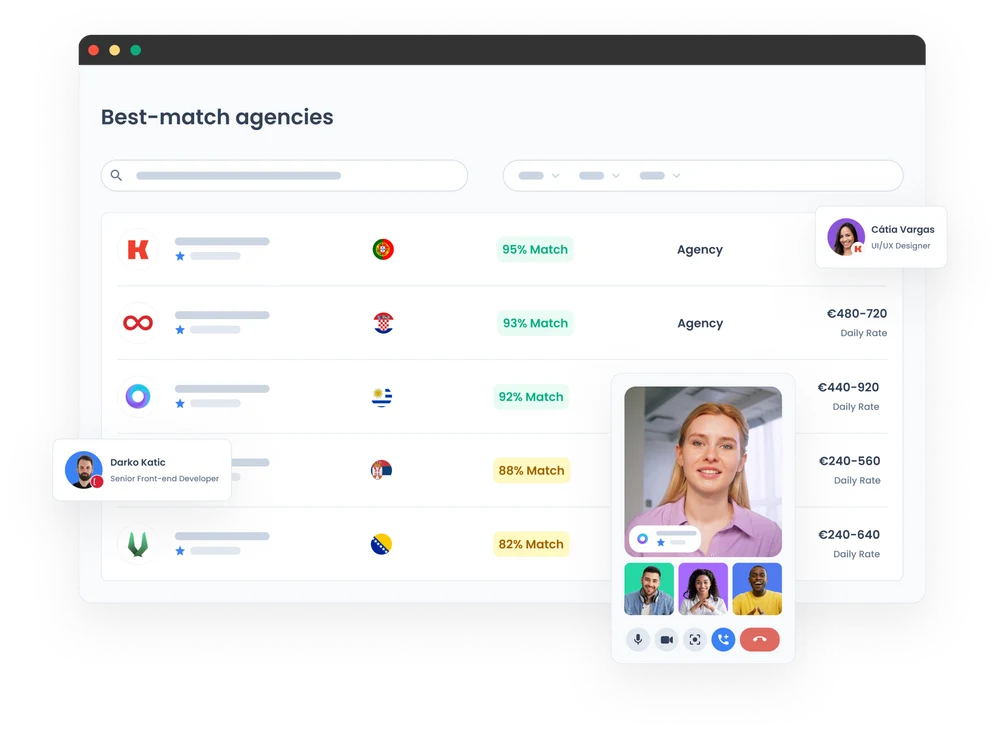
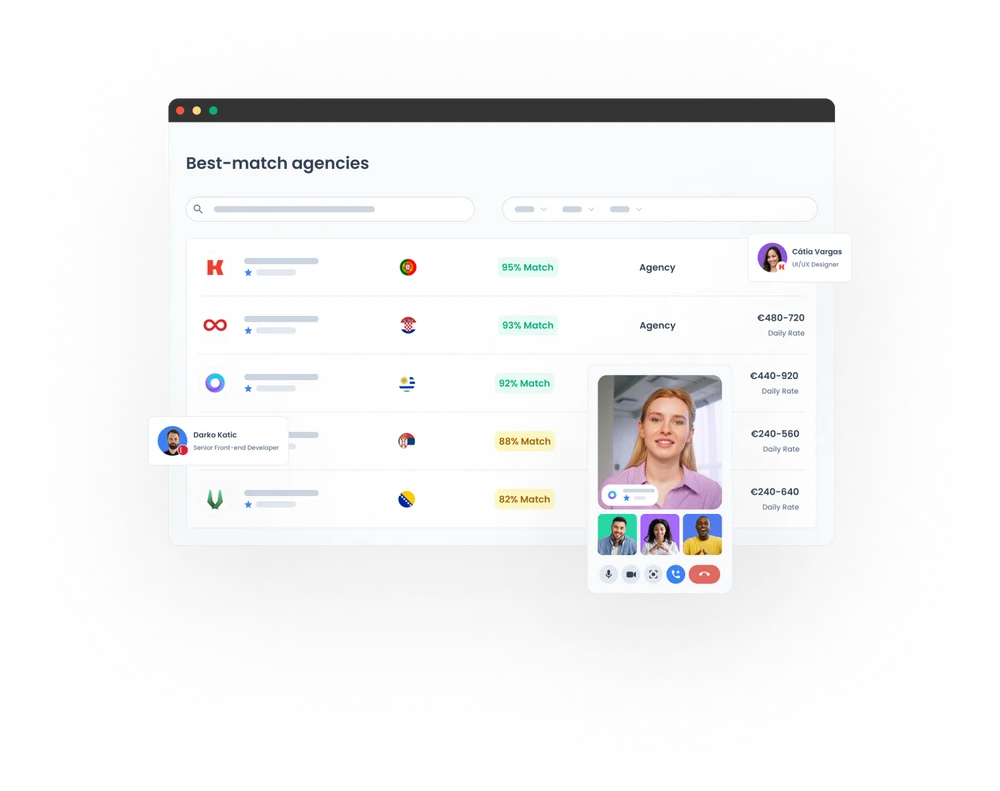
A unified hiring experience in a fragmented market
Hiring quality technologists has become increasingly competitive and challenging. Endless options make it hard to compare and decide.
A unified hiring experience in a fragmented market
Hiring quality technologists has become increasingly competitive and challenging. Endless options make it hard to compare and decide.
There are over 21,000 software development agencies and 600+ talent networks worldwide.
Pangea.ai is the leading talent aggregator that compares the most data points for reliable matching.


Intelligent matching
We compare 100+ data points to find you the best fit

Rigorous vetting
Rigorous due diligence evaluates 500+ expertise, client satisfaction, and team health data points

Customized support
Self-serve your way to a hire or opt for our white-glove matching service